


摘 要:Textrank相比词袋模型有独特的优势,但需要进行多轮迭代和递归运算,常规串行化算法无法满足大数据环境下文档处理的需求。必须借助大数据的分布式处理、并行化计算技术来应对这一挑战。本文学习研究了大数据平台Hadoop的分布式处理方式,并在MapReduce框架下实现并行了Textrank并行提取文档特征的算法。同时,本文就Textrank中关键的投票算法提出了MapReduce迭代实现。经在Hadoop集群上验证,在计算节点增加的情况下,该模式可有效提升Textrank算法效率。
关键词:MapReduce;Textrank;文档特征提取
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2018)10-0080-04
Abstract:Compared with the word bag model,Textrank has unique advantages,but it needs several rounds of iteration and recursive operation. The conventional serialization algorithm can not meet the requirement of document processing in large data environment. It is necessary to deal with this challenge with the help of distributed processing and parallel computing technology of large data. This paper studies the distributed processing method of large data platform Hadoop,and implements parallel Textrank parallel extraction of document features in the framework of MapReduce. Finally,this paper puts forward the idea of MapReduce iterative Realization on the key voting algorithm in Textrank. It is verified by Hadoop cluster that the model can effectively improve the efficiency of Textrank algorithm when the computing node is increased.
Keywords:MapReduce;Textrank;document feature extract
0 引 言
2004年谷歌公布了MapReduce体系结构论文,提出了并行处理模型,查询被切分和发布到并行节点上并行处理(Map阶段),然后再聚集得到结果(Reduce阶段)[1]。后来Apache的开源项目Hadoop实现了MapReduce框架[2]。这种类型的框架让前端应用程序服务器和最终用户对数据处理完全透明[3]。为解决大数据环境下的文档分类及特征抽取,围绕Mapreduce计算框架,很多研究提出了解决方案,文献[4]就Mapreduce框架实现多层神经网络算法提出了方案,文献[5]提出了大数据下用Mapreduce实现K-means聚类的算法设计。文献[6]通过Mapreduce抽取无结构文本中的情感信息等。这些研究分别就Mapreduce并行计算框架在某些特定领域的具体算法进行了尝试,但这些方法基本上是基于词袋模行进行的特征抽取,较少考虑到文本的语义结构信息。
为了有效进行文档分类,我们需要对文档的语义关键词进行提取,进而来实现通过语义关键词进行分类的目的。首先要找到每个文档能够区别其他文档的特征,目前,对文档抽取特征词的方法主要有:基于词袋模型的TF-IDF[7],topic-model[8],基于短语的RAKE算法[9],以基于词序的Textrank[10]等,Textrank是一个基于PageRank[11]的改进算法,即可以根据词的权重对文本提取关键词和摘要。不同于基于词袋的方法,Textrank则从图模型的角度进行文章的关键词的查找,该算法的优点在于事先不用基于大量数据进行训练,它将PageRank中网页的入链数量确定网页得分的原理,改进为让文本中每个词的前后数量投票来确定该词得分,同时并设计了票的权重算法。参考PageRank的计算公式:
1 Mapreduce框架实现Textrank提取文档特征
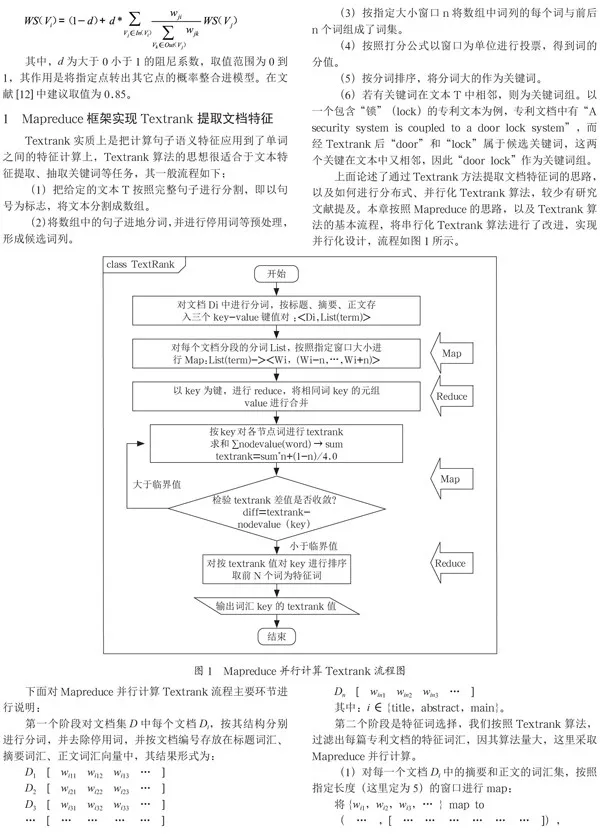
Textrank实质上是把计算句子语义特征应用到了单词之间的特征计算上,Textrank算法的思想很适合于文本特征提取、抽取关键词等任务,其一般流程如下:
(1)把给定的文本T按照完整句子进行分割,即以句号为标志,将文本分割成数组。
(2)将数组中的句子进地分词,并进行停用词等预处理,形成候选词列。
(3)按指定大小窗口n将数组中词列的每个词与前后n个词组成了词集。
(4)按照打分公式以窗口为单位进行投票,得到词的分值。
(5)按分词排序,将分词大的作为关键词。
(6)若有关键词在文本T中相邻,则为关键词组。以一个包含“锁”(lock)的专利文本为例,专利文档中有“A security system is coupled to a door lock system”,而经Textrank后“door”和“lock”属于候选关键词,这两个关键在文本中又相邻,因此“door lock”作为关键词组。
上面论述了通过Textrank方法提取文档特征词的思路,以及如何进行分布式、并行化Textrank算法,较少有研究文献提及。本章按照Mapreduce的思路,以及Textrank算法的基本流程,将串行化Textrank算法进行了改进,实现并行化设计,流程如图1所示。
按此方式,我们在下载文档集上进行了该算法,其效果如图3所示。
2 性能提升测试
为测试将算法改到并行化Mapreduce框架中的性能提升状况,我们组建了hadoop测试集群,主要对Textrank迭代算法运算速度进行测试,通过Mapreduce大数据并行技术,对测试样本2.3G共5万余篇专利文档进行了Textrank特征词提取的测试,整个测试中不同的节点及耗时情况如表1所示。
把以上结果以图例展示可以更明显地看到并行特征提取算法在多节点中性能得到了明显提升。hadoop集群节点数并行计算性能测试表比较如图4所示。
3 结 论
大数据时代文档数量极大、增长极快,传统的分类算法已无法胜任在海量数据环境下的获取及处理需求,需要采取大数据分布式、并行化处理技术去解决这一问题。文章通过研究Textrank文本特征提取算法,并将算法加以改进并移值到Mapreduce算法框架中,经测试,相对传统的串行化处理算法而言,采取大数据并行化计算技术的算法在计算节点增加的情况下,可以有效提高创新知识文档获取的处理性能。
参考文献:
[1] Jeffrey Dean,Sanjay Ghemawat. MapReduce:simplified data processing on large clusters [J].Commun. ACM,2008,51(1):10.
[2] Ghazi M R,Gangodkar D. Hadoop,MapReduce and HDFS:A Developers Perspective [J].Procedia Computer Science,2015,48:45-50.
[3] Boja C,Pocovnicu A,Batagan L. Distributed Parallel Architecture for“Big Data” [J].Informatica Economica Journal,2012,16(2):116-127.
[4] Zhang H J,Xiao N F. Parallel implementation of multilayered neural networks based on Mapreduce on cloud computing clusters [J].Soft Computing,2016,20(4):1471-1483.
[5] Cui X,Zhu P,Yang X,et al. Optimized big data K-means clustering using MapReduce [J].Journal of Supercomputing,2014,70(3):1249-1259.
[6] Ha I,Back B,Ahn B. MapReduce functions to analyze sentiment information from social big data [J].International Journal of Distributed Sensor Networks,2015:1-11.
[7] Salton,Gerard,Buckley,Christopher. Term-weighting approaches in automatic text retrieval [J].Information Processing and Management,1988,24(5):513-523.
[8] Steyvers M,Griffiths T. Probabilistic topic models. [J].IEEE Signal Processing Magazine,2010,27(6):55-65.
[9] Rose S,Engel D,Cramer N,et al. Automatic Keyword Extraction from Individual Documents [M].Text Mining:Applications and Theory. John Wiley Sons,Ltd,2010.
[10] Mihalcea R,Tarau P. Textrank:Bringing Order into Texts [J].Unt Scholarly Works,2004:404-411.
[11] Page L. The PageRank citation ranking:Bringing order to the web [J].Stanford Digital Libraries Working Paper,1998,9(1):1-14.
[12] Brin S,Page L. The anatomy of a large-scale hypertextual Web search engine [J].International Conference on World Wide Web,1998,56(18):107-117.
作者简介:孙龙(1975-),高级软件架构设计师,博士在读。研究方向:软件工程、人工智能和嵌入系统;李彦(1954-),创新方法与创新设计四川省重点实验室主任,创新方法研究会技术创新方法专业委员会副理事长,教授,博士生导师,工学博士。研究方向:人工智能技术在工业中的应用、创新设计理论、方法及应用。
