


摘 要:大数据分析方法很多,通过机器学习构建大数据分析模型进行大数据分析是目前比较有效的方法,大数据特点是数据规模庞大,计算周期长,为了加快计算速度、缩短计算周期,分布式计算方法是解决上述问题行之有效的方法之一。本文介绍了分布式大数据分析模型的构建方法,着重介绍了机器学习算法、分布式计算框架、分布式计算数据处理过程、分布式计算程序设计方法,期望能够为从事大数据分布式计算、大数据分析的研究人员提供一些可借鉴的方法。
关键词:大数据分析;分布式计算;机器学习
中图分类号:TP181 文献标识码:A 文章编号:2096-4706(2018)09-0085-03
Abstract:There are many methods of large data analysis. It is a more effective method to build big data analysis model and analyze big data by machine learning. The large data is characterized by a large scale of data and long computing cycle. In order to speed up the calculation and shorten the calculation period,the distributed computing method is one of the effective methods to solve the above problems. This paper introduces the construction method of distributed large data analysis model,and emphatically introduces machine learning algorithm,distributed computing framework,distributed computing data processing process and distributed computing program design method. It is expected to provide some reference method for researchers who are engaged in large data distributed computing and large data analysis.
Keywords:big data analysis;distributed computation;machine learning
0 引 言
要实现大数据分析分布式计算,首先需要搭建分布式计算平台,然后要建立一个分布式计算框架,在此框架下设计分布式计算模型,编写分布式计算程序。本文通过介绍分布式房价大数据分析模型建立方法,详细介绍了如何实现大数据分布式计算。
1 技术架构
分布式房价大数据分析模型构建的技术架构和技术路线如图1所示,通过爬虫技术在互联网上抓取房地产大数据。大数据存储在分布式存储系统中,分布式存储便于存储设备扩充,通过机器学习构建房价大数据分析模型,通过MapReduce实现分布式计算。
2 分布式计算平台配置
本项目搭建的是Hadoop大数据处理平台,搭建过程中需要配置以下文件:
配置机器网络环境,配置集群列表、环境变量,生成登录秘钥,赋予master节点所属组权利,赋予Node1节点所属组权利,创建Hadoop部署目录、Hadoop数据目录,配置Hadoop环境文件Hadoop-env.sh、JAVA_HOME、Hadoop核心文件core-site.xml、分布式文件系统hdfs-sit.xml、MapReduce文件mapred-sit.xml。[1]
首先配置分布式文件系统,设置分布式文件文件名、分布式文件系统访问端口。设置namesecondary路径,namesecondary作为namenode的备份节点,当namenode失效时namesecondary可以替代namenode。
设置分布式文件系统检查点周期,对datanode和分布式文件进行定期检查,此项目检查周期设为1800秒。设置的间隔时间太短,检查太频繁也会影响分布式文件系统读写速度,间隔时间设置太长,可能不能及时发现分布式文件系统的错误。
设置分布式文件系统检查点大小,对datanode的分布式文件进行定期检查,此项目检查点大小设为33554432字节。*/
设置输入、输出压缩码。
设置垃圾清理间隔时间,本项目设置1440秒。设的间隔时间太短或太长,都会影响分布式文件系统读写速度。
3 房价大数据分布式模型实现
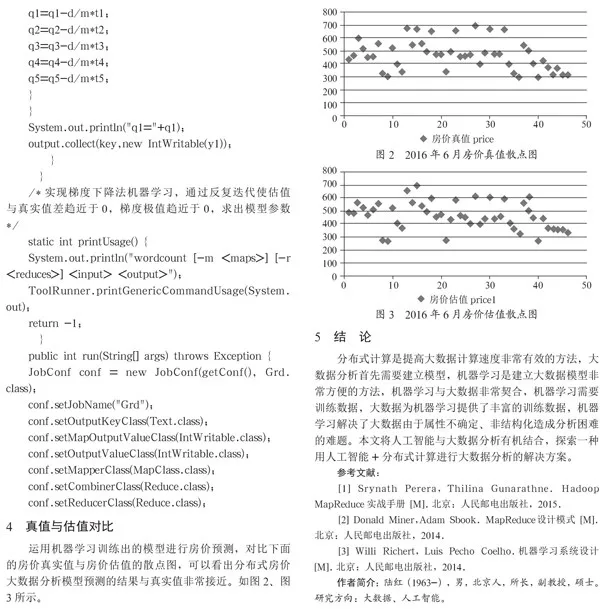
4 真值与估值对比
运用机器学习训练出的模型进行房价预测,对比下面的房价真实值与房价估值的散点图,可以看出分布式房价大数据分析模型预测的结果与真实值非常接近。如图2、图3所示。
5 结 论
分布式计算是提高大数据计算速度非常有效的方法,大数据分析首先需要建立模型,机器学习是建立大数据模型非常方便的方法,机器学习与大数据非常契合,机器学习需要训练数据,大数据为机器学习提供了丰富的训练数据,机器学习解决了大数据由于属性不确定、非结构化造成分析困难的难题。本文将人工智能与大数据分析有机结合,探索一种用人工智能+分布式计算进行大数据分析的解决方案。
参考文献:
[1] Srynath Perera,Thilina Gunarathne. Hadoop MapReduce实战手册 [M].北京:人民邮电出版社,2015.
[2] Donald Miner,Adam Sbook. MapReduce设计模式 [M].北京:人民邮电出版社,2014.
[3] Willi Richert,Luis Pecho Coelho.机器学习系统设计 [M].北京:人民邮电出版社,2014.
作者简介:陆红(1963-),男,北京人,所长,副教授,硕士。研究方向:大数据、人工智能。
